初学爬虫小记

Contents
写博客好累啊,是我太久没有写作了吗
这次来记录一下我第一次学习爬虫的经历
起因
补完とにかくかわいい的番,感觉真好看啊,漫画也不错,就打算补补とにかくかわいい的生肉漫画,但是这网站广告特别多,还会检测我adblocker,禁用javascript的话漫画就加载不出来了,气死我了,一怒之下决定学习爬虫把漫画爬下来看。
爬虫教程有很多,这里特别推荐一个Jack Cui的教程:
爬 manga1001.com
这个网站设置的比较粗糙,图片都是静态加载的(F12就能看见图片链接),根据标签soup.find_all()一下即可。对于这个网站的话,简单说一下爬虫的基本流程吧。
基本流程
-
观察一下页面的HTML,用F12打开可以看到大致结构,如果要看源代码的话,可以选择:
1.1.
res = requests.get(url), print(res.txt)或1.2. 在url前加上
view-source:,然后用浏览器打开。 -
找到包含图片的tag, 找一下规律,然后用
soup.find_all()即可。 -
获取所有章节的URL,然后分别去每个URL里抓取。
参考代码
import requests
from bs4 import BeautifulSoup
import os
import random
import time
def create_dir(path):
if not os.path.exists(path):
os.makedirs(path)
root_folder = '/Users/huzhenwei/Desktop/manga/'
create_dir(root_folder)
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
# get content of one chapter
def get_content(folder, prefix, url):
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
items = soup.find_all('figure')
i = 1
folder_name = os.path.join(folder, f'Chapter_{prefix:03}/')
create_dir(folder_name)
for item in items:
for child in item.children:
if i != 1:
img_url = child.get('data-src')
else:
img_url = child.get('src')
print(img_url)
headers = random.choice(USER_AGENTS)
img_html = requests.get(img_url, headers)
img_name = os.path.join(folder_name, f'{i:02}.jpg')
with open(img_name, 'wb') as file:
file.write(img_html.content)
file.flush()
i += 1
time.sleep(random.uniform(0, 3.33)) # sleep random time
# get manga url list
def get_url_list(manga_name, url):
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
items = soup.find_all('option')
for i in range(len(items) - 2, -1, -1):
if items[i] == items[-1]: # get manga chapter url list without duplicates
items = items[i+1:]
break
chapter = 1
folder = os.path.join(root_folder, f'{manga_name}/')
for item in items:
manga_url = item.get('value')
get_content(folder, chapter, manga_url)
print(manga_url)
chapter += 1
def main():
url1 = "https://manga1001.com/%e3%80%90%e7%ac%ac1%e8%a9%b1%e3%80%91%e3%83%88%e3%83%8b%e3%82%ab%e3%82%af%e3%82%ab%e3%83%af%e3%82%a4%e3%82%a4-raw/"
name1 = 'Tonikaku_Kawaii'
get_url_list(name1, url1)
url2 = "https://manga1001.com/%e3%80%90%e7%ac%ac1%e8%a9%b1%e3%80%91%e5%b9%b2%e7%89%a9%e5%a6%b9%e3%81%86%e3%81%be%e3%82%8b%e3%81%a1%e3%82%83%e3%82%93-raw/"
name2 = 'Umaru_Chan'
get_url_list(name2, url2)
main()
注: 这里用的
USER_AGENT和sleep()都是为了防止被发现然后封IP
爬 manhuagui.com
上面那个太没挑战性了,于是我打算再爬一个。
打开漫画网站,
 发现没有图片链接,说明是动态加载的图片(用javascript加载的),那怎么办呢?
发现没有图片链接,说明是动态加载的图片(用javascript加载的),那怎么办呢?
Step 1
先在网页里找找链接长啥样,毕竟用浏览器浏览的话,图片总是会被加载出来的,然后就能看到链接了,果然,在chrome的Elements这个tag里,我们翻到了图片链接:
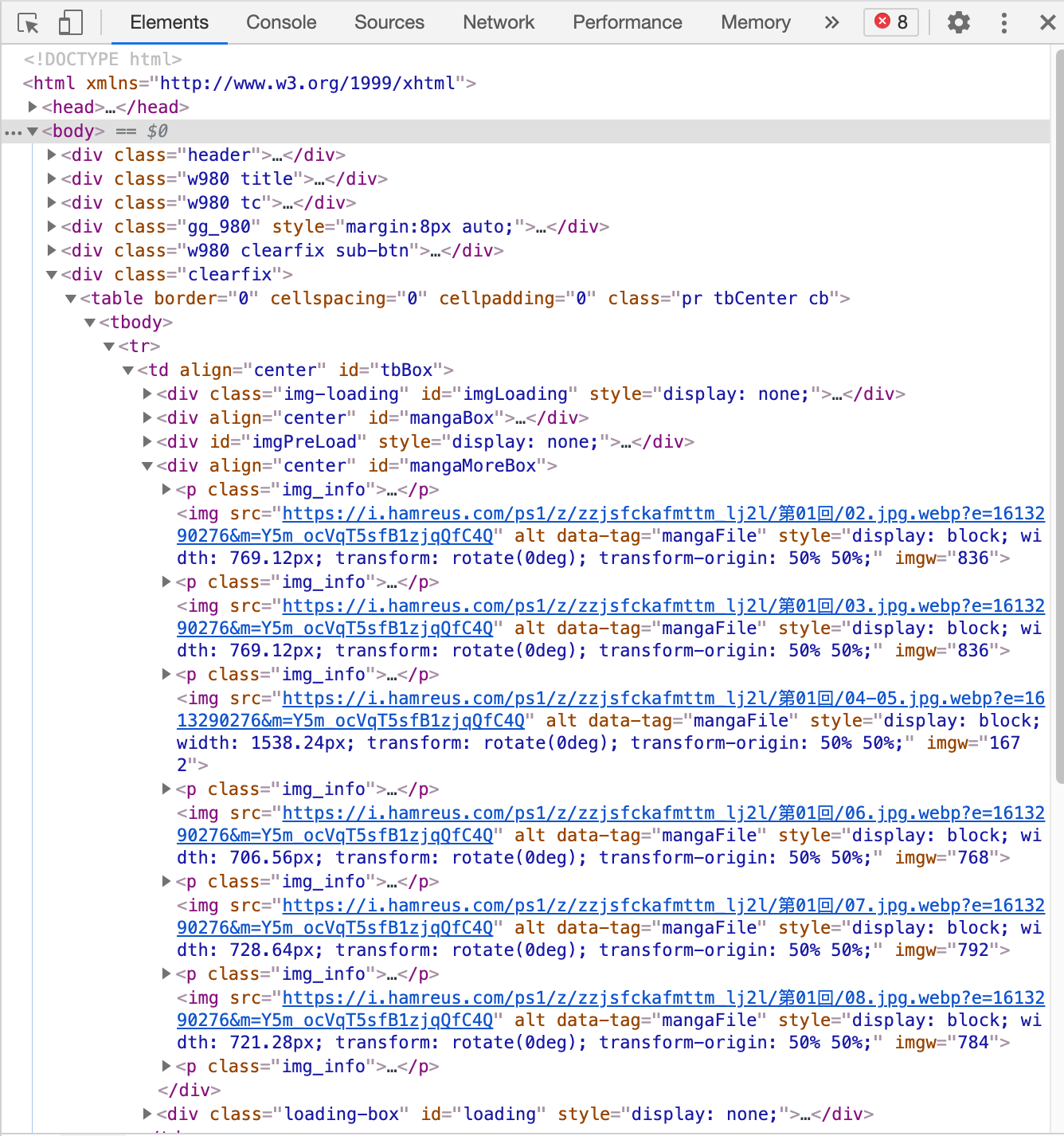
不过直接把链接复制到浏览器里打开的话会403,所以我们先搁置一下。
Step 2
我们要获得某一话的所有图片链接,可以从图上看出似乎有一大段像是加密后的字符串,我们打开第一话和第二话的HTML,用命令行diff一下以后,会发现差异就刚好出现在这串字符串上: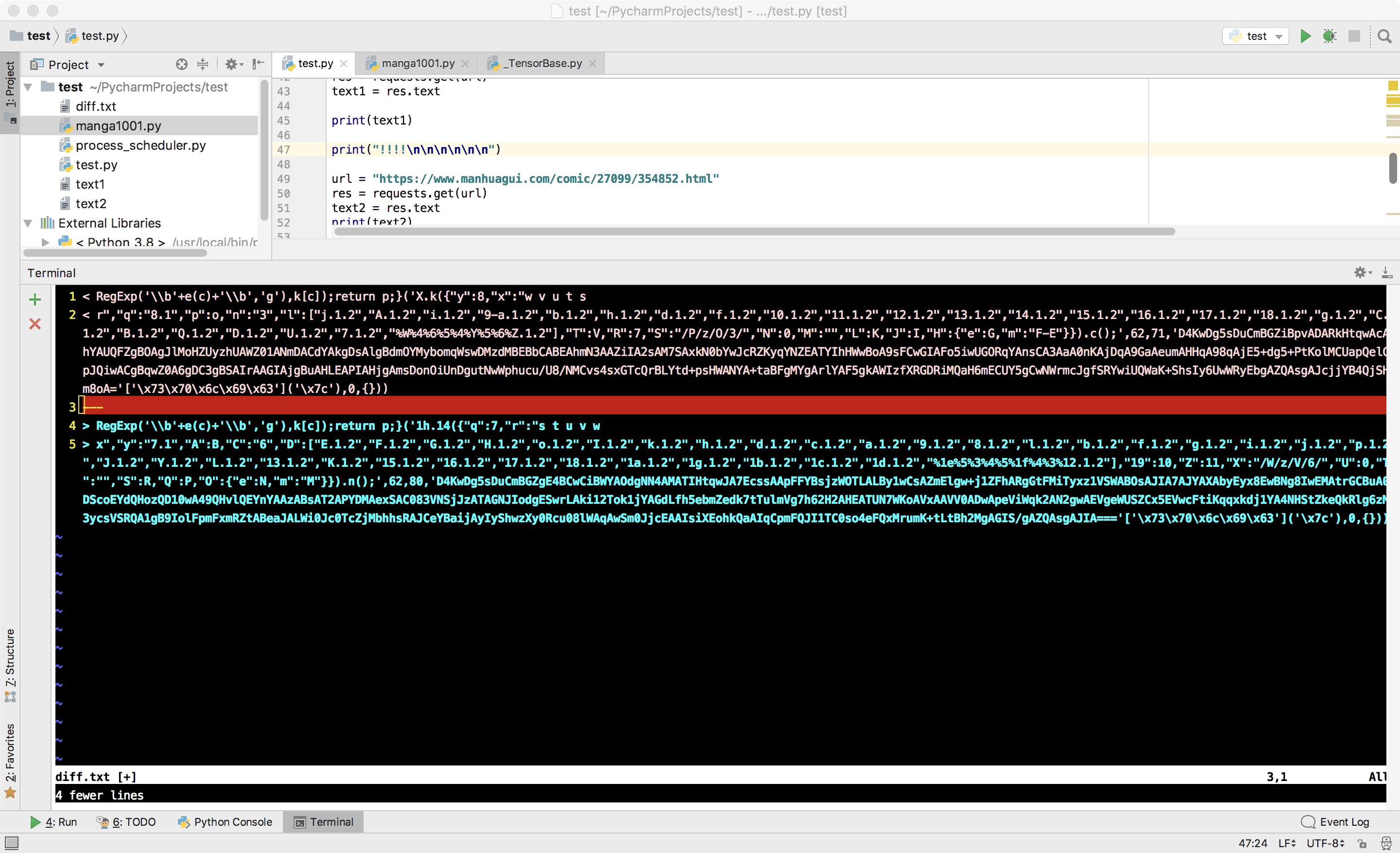 我们可以肯定这里面包含了图片链接相关的信息。
我们可以肯定这里面包含了图片链接相关的信息。
Step 3
既然找到了加密串,那就要找一个钥匙来解码,看一下网页里内容不多,看起来并没有其他有用信息了,但是还有几个.js文件,一个个打开来看一下,终于在其中一个文件里找到了一大堆代码,然后这一大堆里面,有一段看起来又被加密了(有点此地无银三百两啊):

把这段代码复制到chrome的console里,发现被自动解码了,得到了一个js函数:
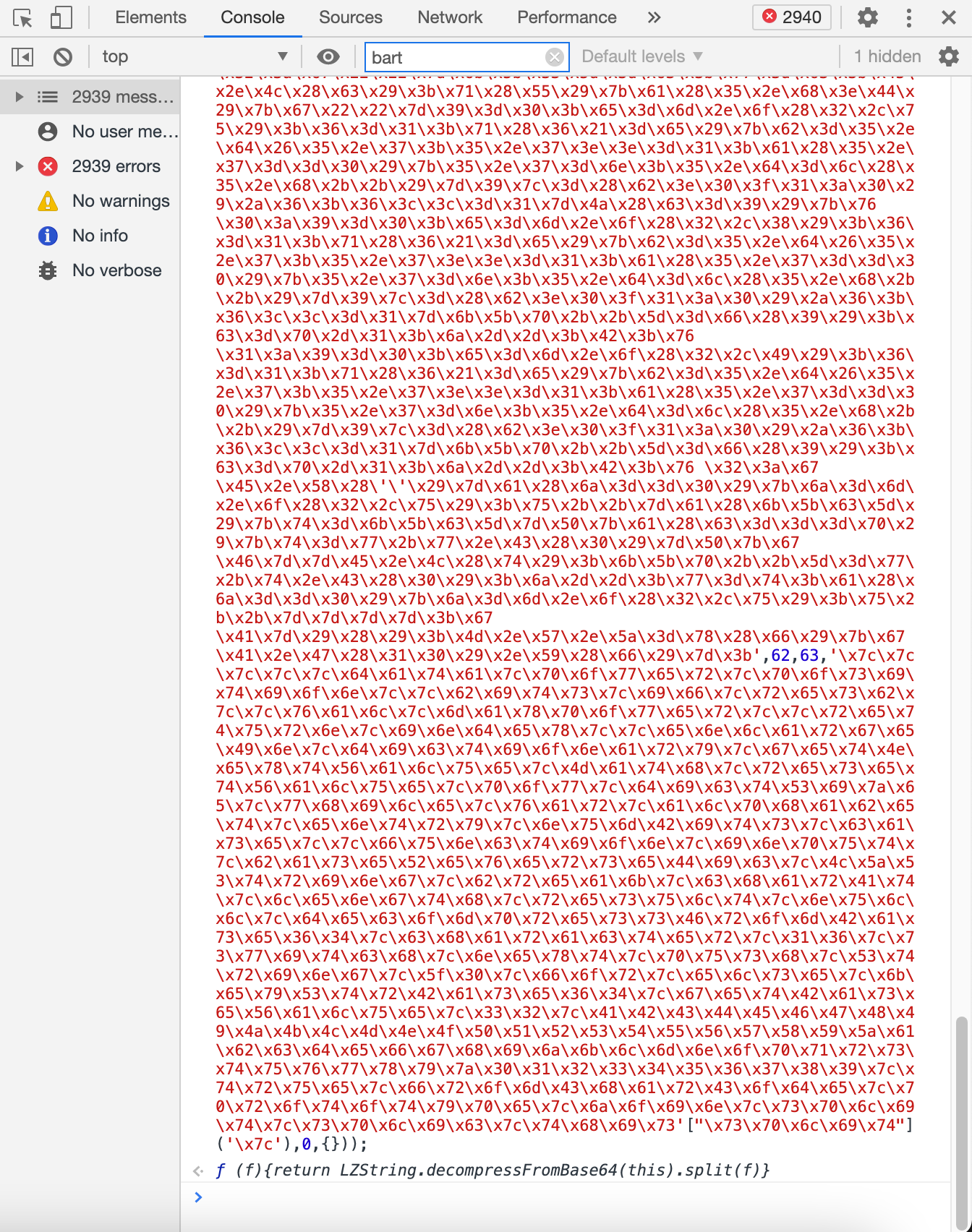
我们点开这个函数,看一下里面的内容:
函数内容
var LZString=(function(){var f=String.fromCharCode;var keyStrBase64="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";var baseReverseDic={};function getBaseValue(alphabet,character){if(!baseReverseDic[alphabet]){baseReverseDic[alphabet]={};for(var i=0;i<alphabet.length;i++){baseReverseDic[alphabet][alphabet.charAt(i)]=i}}return baseReverseDic[alphabet][character]}var LZString={decompressFromBase64:function(input){if(input==null)return"";if(input=="")return null;return LZString._0(input.length,32,function(index){return getBaseValue(keyStrBase64,input.charAt(index))})},_0:function(length,resetValue,getNextValue){var dictionary=[],next,enlargeIn=4,dictSize=4,numBits=3,entry="",result=[],i,w,bits,resb,maxpower,power,c,data={val:getNextValue(0),position:resetValue,index:1};for(i=0;i<3;i+=1){dictionary[i]=i}bits=0;maxpower=Math.pow(2,2);power=1;while(power!=maxpower){resb=data.val&data.position;data.position>>=1;if(data.position==0){data.position=resetValue;data.val=getNextValue(data.index++)}bits|=(resb>0?1:0)*power;power<<=1}switch(next=bits){case 0:bits=0;maxpower=Math.pow(2,8);power=1;while(power!=maxpower){resb=data.val&data.position;data.position>>=1;if(data.position==0){data.position=resetValue;data.val=getNextValue(data.index++)}bits|=(resb>0?1:0)*power;power<<=1}c=f(bits);break;case 1:bits=0;maxpower=Math.pow(2,16);power=1;while(power!=maxpower){resb=data.val&data.position;data.position>>=1;if(data.position==0){data.position=resetValue;data.val=getNextValue(data.index++)}bits|=(resb>0?1:0)*power;power<<=1}c=f(bits);break;case 2:return""}dictionary[3]=c;w=c;result.push(c);while(true){if(data.index>length){return""}bits=0;maxpower=Math.pow(2,numBits);power=1;while(power!=maxpower){resb=data.val&data.position;data.position>>=1;if(data.position==0){data.position=resetValue;data.val=getNextValue(data.index++)}bits|=(resb>0?1:0)*power;power<<=1}switch(c=bits){case 0:bits=0;maxpower=Math.pow(2,8);power=1;while(power!=maxpower){resb=data.val&data.position;data.position>>=1;if(data.position==0){data.position=resetValue;data.val=getNextValue(data.index++)}bits|=(resb>0?1:0)*power;power<<=1}dictionary[dictSize++]=f(bits);c=dictSize-1;enlargeIn--;break;case 1:bits=0;maxpower=Math.pow(2,16);power=1;while(power!=maxpower){resb=data.val&data.position;data.position>>=1;if(data.position==0){data.position=resetValue;data.val=getNextValue(data.index++)}bits|=(resb>0?1:0)*power;power<<=1}dictionary[dictSize++]=f(bits);c=dictSize-1;enlargeIn--;break;case 2:return result.join('')}if(enlargeIn==0){enlargeIn=Math.pow(2,numBits);numBits++}if(dictionary[c]){entry=dictionary[c]}else{if(c===dictSize){entry=w+w.charAt(0)}else{return null}}result.push(entry);dictionary[dictSize++]=w+entry.charAt(0);enlargeIn--;w=entry;if(enlargeIn==0){enlargeIn=Math.pow(2,numBits);numBits++}}}};return LZString})();String.prototype.splic=function(f){return LZString.decompressFromBase64(this).split(f)};
获得这个函数以后,我们尝试着把之前获得的加密串放进去看看:

这看起来就正常多了,而且这里面的 04|05|06|... 之类的信息看起来也能和之前找到的图片链接对应上。但是它似乎并没有按照某个特定的规律来,所以可以肯定还有一个函数来处理这个字符串。
Step 4
有了这个信息,我们就接着找处理这个字符串的函数,再次观察一下HTML,发现这个Base64的串被包含在了一个<script>当中,长这样:
script内容
<script type="text/javascript">window["\x65\x76\x61\x6c"](function(p,a,c,k,e,d){e=function(c){return(c<a?"":e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)d[e(c)]=k[c]||e(c);k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1;};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p;}('X.B({"y":8,"x":"w v u t s r","q":"8.1","p":o,"n":"4","l":["j.1.2","A.1.2","h.1.2","9-a.1.2","b.1.2","c.1.2","d.1.2","f.1.2","10.1.2","11.1.2","12.1.2","13.1.2","14.1.2","15.1.2","16.1.2","17.1.2","g.1.2","k.1.2","C.1.2","P.1.2","D.1.2","U.1.2","W.1.2","3.1.2","%Y%5%7%6%5%Z%6%7%T.1.2"],"V":R,"Q":3,"S":"/O/z/N/4/","M":0,"L":"","K":J,"I":H,"G":{"e":F,"m":"E"}}).i();',62,70,'D4KwDg5sDuCmBGZgCYCsxA03gBgIyD21YADgCFgBRdATlOQHYtLLgsAWZ9LANmducOGZMc/LAGZgYAE6wAkgDsAlgBdmOYDiYAzBQBtYAZwEBjOQEMAtrGCjULUZSzAjCgCbBECo8HMB7H3OAlAAsrJR9vK00dAE9gQG4DQGk5QEYdQHozQD10wA49QHvlQEYndzNLd1cBLGRgBXMIABFTJVMUR2QygE1UcwB9HyMANQBHABVUfU1iHAAvEF6ARU0AYRYp9U4cUWQHOm59HSXOQmQ1KVgANxk3GxZUSm45WAAPJVP3HS6Aa3ajL306pQBXQzGJsMjC9TJpzEolB0dCBkNswPo1PtgHoAppTDp9FYwLUgsBiGQUOJtIp9CE3Mg2ABlACyAAlyNxKAAxASs1lAA==='['\x73\x70\x6c\x69\x63']('\x7c'),0,{})) </script>
看起来这也是一个函数啊,而且这个Base64的串似乎作为参数了,再次动用chrome的console帮助我们解析一下:
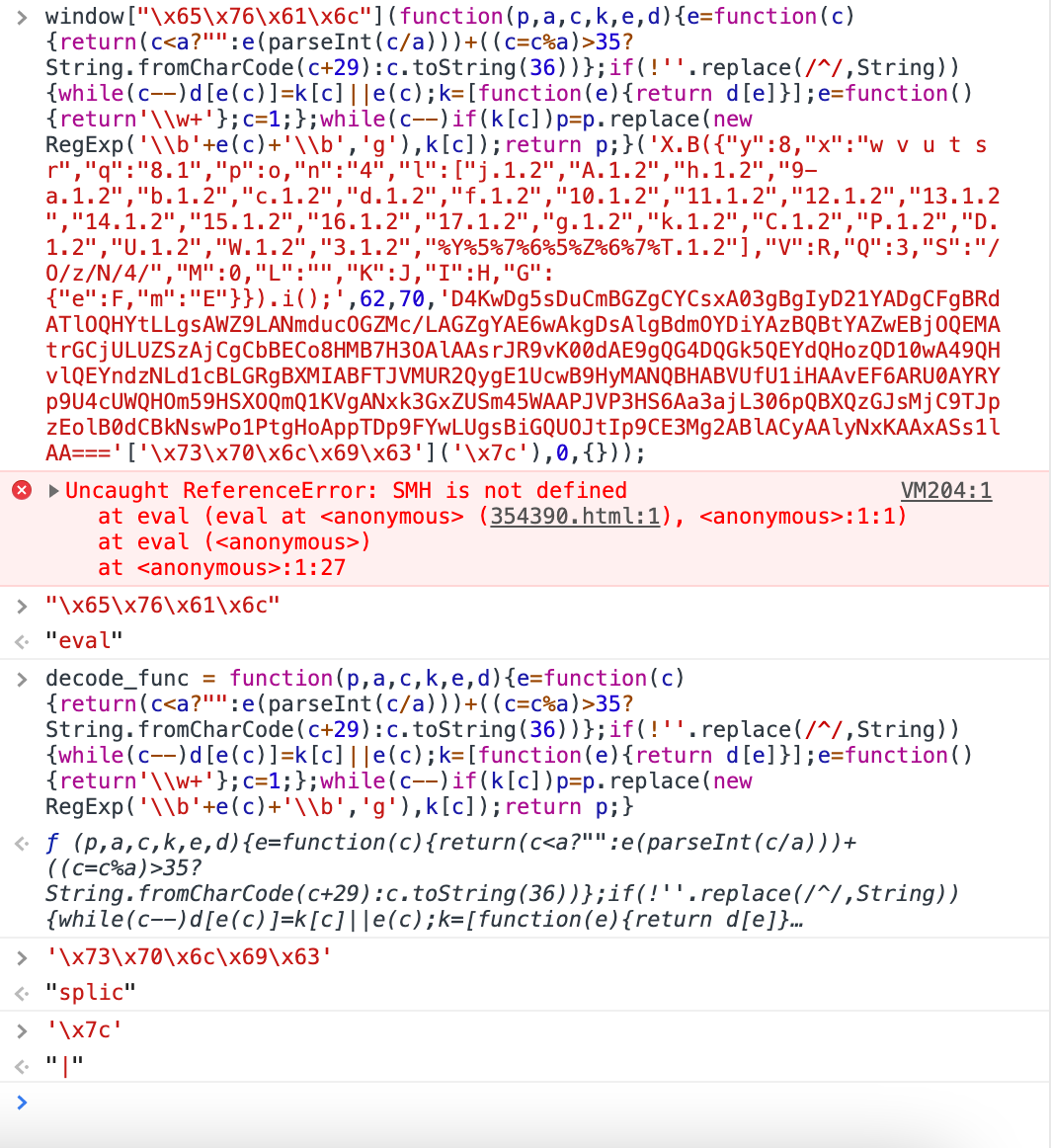
这下我们大概可以明白几个事情:
- 这段代码实际上是
window["eval"](...) - 省略号部分是一个函数
function(p,a,c,k,e,d), 以{}包起来的是函数内容,那return p;}后面的想必就是这6个参数。
观察一下这6个参数,我们会发现:
p = 'X.B({"y":8,"x":"w v u t s r","q":"8.1","p":o,"n":"4","l":["j.1.2","A.1.2","h.1.2","9-a.1.2","b.1.2","c.1.2","d.1.2","f.1.2","10.1.2","11.1.2","12.1.2","13.1.2","14.1.2","15.1.2","16.1.2","17.1.2","g.1.2","k.1.2","C.1.2","P.1.2","D.1.2","U.1.2","W.1.2","3.1.2","%Y%5%7%6%5%Z%6%7%T.1.2"],"V":R,"Q":3,"S":"/O/z/N/4/","M":0,"L":"","K":J,"I":H,"G":{"e":F,"m":"E"}}).i();'
a = 62, c = 70
k = 'D4KwDg5sDuCmBGZgCYCsxA03gBgIyD21YADgCFgBRdATlOQHYtLLgsAWZ9LANmducOGZMc/LAGZgYAE6wAkgDsAlgBdmOYDiYAzBQBtYAZwEBjOQEMAtrGCjULUZSzAjCgCbBECo8HMB7H3OAlAAsrJR9vK00dAE9gQG4DQGk5QEYdQHozQD10wA49QHvlQEYndzNLd1cBLGRgBXMIABFTJVMUR2QygE1UcwB9HyMANQBHABVUfU1iHAAvEF6ARU0AYRYp9U4cUWQHOm59HSXOQmQ1KVgANxk3GxZUSm45WAAPJVP3HS6Aa3ajL306pQBXQzGJsMjC9TJpzEolB0dCBkNswPo1PtgHoAppTDp9FYwLUgsBiGQUOJtIp9CE3Mg2ABlACyAAlyNxKAAxASs1lAA==='['split']('|')
e = 0, d = {}
唯一需要处理的似乎就是k了,虽然k里没有|这个符号,不过刚才使用LZString.decompressfromBase64()函数解析出来的东西倒是有很多|。
自此真相大白了,我们需要做的事情很简单:
- 提取出
p,a,c,k,e,d这6个参数。 - 将
k放进LZString.decompressfromBase64()解析一下。 - 调用
decode_func(也就是function(p,a,c,k,e,d)),得到结果。
结果长这样:

我们要的图片链接就找到啦!在 files 里。
Step 5:
我们还剩下最后一个问题:有了图片链接但是访问不了(403)怎么办?这似乎是一种简单的反爬虫方式,google一下,只要假装我们是从本站(即这个漫画的网站)进去的,而不是从其他地方进去的,就可以访问了。虽然在浏览器上做不到,但是python里可以通过更改Referer的方式来达到:
def get_download_header():
return {'User-Agent': random.choice(USER_AGENTS), "Referer": "https://www.manhuagui.com/comic/27099/"}
Step 6:
最后的最后,就是爬虫的基本过程了,不过我们有一段javascript代码需要运行,怎么在python中运行javascript呢?
- 首先保存一下javascript代码,叫
decode_func.js。内容如下:
const jsdom = require("jsdom");
const { JSDOM } = jsdom;
const dom = new JSDOM(`<!DOCTYPE html><p>Hello world</p>`);
window = dom.window;
document = window.document;
XMLHttpRequest = window.XMLHttpRequest;
decode_func = window["eval"](function(p,a,c,k,e,d){e=function(c){return(c<a?"":e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)d[e(c)]=k[c]||e(c);k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1;};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p;})
- 然后用以下这段代码就可以了:
def load_js():
with open("decode_func.js", 'r') as file:
js = file.read()
context = execjs.compile(js, cwd="/usr/local/lib/node_modules")
return context
context = load_js()
调用的时候就用
res = context.call(("decode_func"), p,a,c,k,e,d)
最终代码如下:
参考代码
import requests
from bs4 import BeautifulSoup
import os
import time
import random
import lzstring
import execjs
import re
import json
def create_dir(path):
if not os.path.exists(path):
os.makedirs(path)
root_folder = '/Users/huzhenwei/Desktop/manga/'
create_dir(root_folder)
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
def get_download_header():
return {'User-Agent': random.choice(USER_AGENTS), "Referer": "https://www.manhuagui.com/comic/27099/"}
def load_js():
with open("decode_func.js", 'r') as file:
js = file.read()
context = execjs.compile(js, cwd="/usr/local/lib/node_modules")
return context
context = load_js()
def decode(s):
x = lzstring.LZString()
decoded_str = x.decompressFromBase64(s)
return decoded_str.split("|")
# p = """1h.14({"q":7,"r":"s t u v w x","y":"7.1","A":B,"C":"6","D":["E.1.2","F.1.2","G.1.2","H.1.2","o.1.2","I.1.2","k.1.2","h.1.2","d.1.2","c.1.2","a.1.2","9.1.2","8.1.2","l.1.2","b.1.2","f.1.2","g.1.2","i.1.2","j.1.2","p.1.2","J.1.2","Y.1.2","L.1.2","13.1.2","K.1.2","15.1.2","16.1.2","17.1.2","18.1.2","1a.1.2","1g.1.2","1b.1.2","1c.1.2","1d.1.2","%1e%5%3%4%5%1f%4%3%12.1.2"],"19":10,"Z":11,"X":"/W/z/V/6/","U":0,"T":"","S":R,"Q":P,"O":{"e":N,"m":"M"}}).n();"""
# a,c = 62,80
# k=['', 'jpg', 'webp', '9B', 'E5', '8B', '第02回', '27099', 'P0056', 'P0055', 'P0054', 'P0058', 'P0053', 'P0052', '', 'P0059', 'P0060', 'P0051', 'P0061', 'P0062', 'P0050', 'P0057', '', 'preInit', 'P0048', 'P0063', 'bid', 'bname', '总之就是非常可爱', 'fly', 'me', 'to', 'the', 'moon', 'bpic', '', 'cid', '354852', 'cname', 'files', 'P0044', 'P0045', 'P0046', 'P0047', 'P0049', 'P0064', 'P0068', 'P0066', 'GYeIdl7ujUrxJ1ls7JvwpQ', '1612951385', 'sl', '354596', 'prevId', '356912', 'nextId', 'block_cc', 'status', 'zzjsfckafmttm_lj2l', 'ps1', 'path', 'P0065', 'len', 'false', '35', 'BE', 'P0067', 'imgData', 'P0069', 'P0070', 'P0071', 'P0072', 'finished', 'P0073', 'P0075', 'P0076', 'P0077', 'E6', '9F', 'P0074', 'SMH']
# e = 0
# d = dict()
# res = context.call(("decode_func"), p,a,c,k,e,d)
# print(type(res))
# print(res)
# get content of one chapter
def get_content(title, url):
create_dir(os.path.join(root_folder, title))
res = requests.get(f"https://manhuagui.com{url}", random.choice(USER_AGENTS))
# print(res.text)
soup = BeautifulSoup(res.content, 'html.parser')
items = soup.find_all(lambda tag:tag.name=='script', recursive=True)
for item in items:
txt = item.string # 必须是item.string, 不能是item.txt
if txt and "return p;" in txt: # 如果tag里没有文字,txt==None
parts = txt.split("return p;}(")
part = parts[1][:-2]
split_res = re.split(r',([0-9]+,[0-9]+,)', part)
p = split_res[0][1:-1]
split_res[1] = split_res[1][:-1]
a, c = map(int, split_res[1].split(','))
k = split_res[2].split("'['")[0][1:]
k = decode(k)
e = 0
d = dict()
res = context.call(("decode_func"), p,a,c,k,e,d)
s = re.search('({.+})', res).group(0) # 找到一个由 {} 包裹的group
info_dict = json.loads(s)
files_list = info_dict["files"]
path_prefix = 'https://i.hamreus.com' + info_dict["path"]
i = 1
for file_name in files_list:
complete_path = path_prefix + file_name[:-5]
print(complete_path)
res = requests.get(complete_path, headers=get_download_header())
img_name = os.path.join(root_folder, title, f'{i}.jpg')
with open(img_name, 'wb') as file:
file.write(res.content)
file.flush()
time.sleep(random.uniform(5.0, 10.0))
i += 1
# get manga url list
def get_url_list(url):
res = requests.get(url, random.choice(USER_AGENTS))
soup = BeautifulSoup(res.content, 'html.parser')
items = soup.find_all('div', {"id": "chapter-list-1"})
for manga_list in items:
links = manga_list.find_all("a", recursive=True)
links = links[1:]
for link in links:
title = link.get("title")
ref = link.get("href")
if title[-1] == '卷':
continue
print(f"{title}, {ref}")
get_content(title, ref)
url = "https://www.manhuagui.com/comic/27099/"
get_url_list(url)
注:上面这块代码被识别成lua语言了,样式出了点问题,可以在markdown里面指定语言,在第一个
```后面加上语言名即可,如```python
后记
写这篇blog比玩爬虫本身还累啊,看来我果然不适合写作文(虽然我从小就深刻的明白这个道理)。不过这篇博客很大程度上也是写给自己看的,作为下次爬虫的参考(不知道下次爬虫要等到什么时候了)。
以后可能会补点儿算法笔记,或者题解之类的。